

Vivimos en un mundo lleno de datos y cuando están debidamente organizados, analizados e interpretados, esos datos son una herramienta poderosa que está produciendo grandes avances en diferentes disciplinas, incluyendo la salud pública.
¿Qué pasa en internet durante 1 minuto?
En 2017, la consultora Cumulus Media publicó una infografía sobre la actividad que el conjunto de usuarios de Internet realizaba durante 1 minuto para mostrar a las radios cómo se dividía la atención de su audiencia entre la escucha y otras actividades en las pantallas.
De acuerdo con la información compilada por Lori Lewis y Chad Callahan1, en 2019, durante 1 minuto de Internet, 1 millón personas se conectan a Facebook, se reproducen 4,5 millones de video en YouTube, se envían 188 millones de emails y 41,6 millones de mensajes (WhatsApp/Messenger), se miran 694.444 horas de contenido de Netflix, se realizan 3,8 millones de búsquedas en Google (Figura 1).

Figura 1. ¿Qué ocurre en 1 minuto de Internet en 2019?
This is what happens in an Internet minute, Lori Lewis y Chad Callahan. Recuperado de: https://lorilewismedia.com/
Big data
La masividad de datos y el abaratamiento de los costos de su recolección, gestión y procesamiento son responsables por la actual pasión por los datos. El auge de big data se refiere a la masiva disponibilidad de datos generada por Internet y otros mecanismos electrónicos de interacción social.
Sin embargo, este fervor por los datos, big data o datos masivos, trae algunas controversias. Ciertos críticos cuestionan cómo se analizarán y utilizarán esos datos, ya que los beneficios no provienen simplemente de la disponibilidad de los datos, sino de su correcto procesamiento estadístico y de su interpretación.
“Big Data” son datos cuyo volumen, diversidad y complejidad requieren nuevos equipamientos, técnicas y métodos de análisis para gestionar y extraer valor y conocimiento a partir de ellos.
Esa copiosa cantidad de datos producidos espontáneamente por la interacción con dispositivos interconectados se caracteriza por 3 V: volumen, velocidad, variedad.
• Volumen: Big data implica un volumen enorme de datos. Los datos son generados automáticamente por sensores, dispositivos móviles e interacciones personales en redes sociales y los volúmenes a analizar son masivos.
• Velocidad: se generan a una velocidad que los hace disponibles en tiempo real por lo que la velocidad está asociada a un procesamiento y análisis rápido de datos. El flujo de datos no sólo es masivo, sino que también es continuo.
• Variedad: la variedad se refiere a las diferentes fuentes y tipos de datos, tanto estructurados como no estructurados. Hace pocos años los únicos datos que se almacenaban provenían de hojas de cálculo y bases de datos. Además de los datos recogidos por gobiernos a través de censos y encuestas, hoy se almacenan muchos otros datos: todas nuestras actividades en internet (datos de compras en línea, hora de entrada a red, productos consultados, cuándo se compró); historias clínicas electrónicas: cuándo vamos al médico, en qué época del año, resultados de análisis de laboratorio, imágenes, etc.
Los datos generados son de naturaleza espontánea, anárquica y amorfa, llegan en la forma de emails, fotos, videos, sensores, archivos de audio, etc. Esa variedad de datos debe ser estructurada y sistematizada para que puedan ser analizados. La sistematización es una de las tareas más importantes.
Hay autores que agregan una cuarta V: veracidad. En investigación clínica, por ejemplo, los datos se obtienen de ensayos clínicos aleatorizados en los que la calidad de la información obtenida es muy elevada, aunque existe el problema de que esos estudios tienen una duración relativamente corta, además de que el grupo de pacientes es restringido y selecto. Los datos tomados de la práctica habitual del médico tienen la ventaja de provenir de la vida real, a lo que se suman como ventajas el mayor número de pacientes y la posibilidad de hacer un seguimiento a más largo plazo; pero no tienen la sistematización y alta calidad de los datos obtenidos en un ensayo clínico.
Veracidad: ¿qué tan precisos y confiables son los datos obtenidos y el método de procesamiento elegido? Se debe evaluar el posible sesgo y determinar nivel de incertidumbre debido a inconsistencias de datos, datos incompletos, aproximaciones de modelos. Al verificar la calidad de los datos, debe considerarse si los datos están directamente relacionados y son significativos en relación con el problema que se quiere analizar. Obtener datos correctos según el uso previsto y mantener datos limpios en los sistemas es un aspecto clave para poder tomar las decisiones correctas.
La velocidad de recogida de datos es importante, pero más importante es su velocidad de análisis. ¿Cómo creció la capacidad de almacenamiento de datos en los últimos 25 años? (Tabla 1)
En los últimos dos años, hemos creado más datos que en toda la historia de la humanidad.
Se estima que el mundo almacenó unos 4 zettabytes (4 x 1021 bytes) en 2013 y se espera que todo el universo digital alcance 44 zettabytes en 20203. Hubiera sido imposible en ese entonces almacenar y analizar esta increíble cantidad de datos que se generan actualmente.
Tabla 1. Capacidad de almacenamiento de distintos medios

Ciencia de datos
La ciencia de datos combina el método científico tradicional con la habilidad de explorar y lograr una visión profunda de los datos. Además, la ciencia de datos necesita la interacción de distintas disciplinas que tienen en común la necesidad de manejar grandes cantidades de información. Se trata de un trabajo en equipo entre programadores, bioinformáticos, expertos en un área del conocimiento, estadísticos. Se dice que encontrar a alguien altamente capacitado en todas estas áreas es como buscar un unicornio.
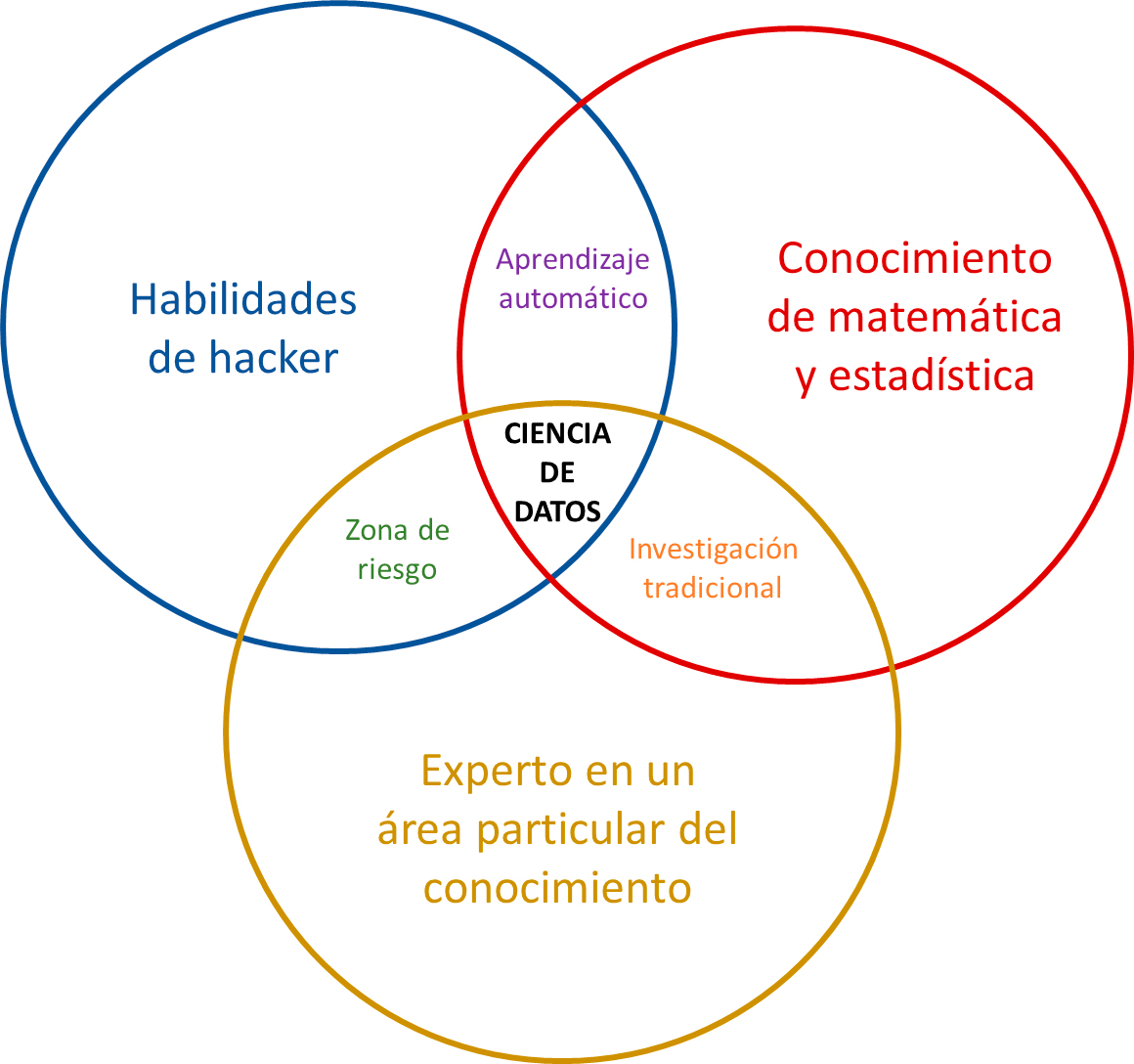
Figura 2. El diagrama de Venn de la ciencia de datos
Traducido y adaptado de “The Data Science Venn Diagram”, Drew Conway. Recuperado de: http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram, bajo licencia Creative Commons Atribución-No comercial.
Una vez que se obtienen los datos de interés, sin necesidad de ser un hacker, esos datos deben ser limpiados y ordenados para luego aplicar los métodos matemáticos y estadísticos apropiados para su descripción y análisis. Para llegar a la “ciencia” de datos, debe haber un interés en responder una pregunta que aporte a la construcción de conocimiento, por lo que se necesita conocimiento y experiencia en esa área del saber. La mayoría de los investigadores “tradicionales” conjugan conocimientos de matemática y estadística con los conocimientos propios de su área de investigación.
El aprendizaje automático (Machine Learning, en inglés) es la capacidad de un programa de aprender a hacer una tarea cada vez mejor, en base a la experiencia. Se trata de un área del conocimiento que combina conocimientos de computación, matemática y estadística.
El área señalada como “Zona de riesgo” en la Figura 2 se refiere a quienes cuentan con las habilidades para extraer datos y estructurarlos, sumado a ser un experto en un área del conocimiento, pero les falta el conocimiento estadístico para interpretar esos datos.
Sería el caso de Funes el memorioso: muchos datos sin las habilidades necesarias para interpretarlos y comprender. Ireneo Funes es el personaje del cuento “Funes el memorioso” publicado por Jorge Luis Borges en 1942. Funes podía recordar absolutamente todo, podía reconstruir todos los días hasta el más mínimo detalle, pero era incapaz de comprender. Según Borges, “Pensar es olvidar diferencias, es generalizar, abstraer. En el abarrotado mundo de Funes no había sino detalles”. La relación entre Funes el memorioso y big data sin estadística fue planteada por un profesor del Departamento de Estadística de la Universidad de Chicago Stephen M. Stigler en su libro Los siete pilares de la sabiduría estadística.
Es necesario contar con recursos humanos preparados para generar una estrategia adecuada para la ciencia de datos. Es un área emergente y en expansión y una oportunidad para la investigación y el desarrollo en los próximos años.
Entonces, no se trata de acumular o buscar datos porque sí, sino de, como en toda investigación, partir de una pregunta que queremos responder sobre un problema no resuelto, plantear una hipótesis de trabajo, objetivos, un diseño experimental, etc.
No se debe dejar de pensar en las limitaciones legales y éticas que puede tener esta investigación. ¿Los datos son públicos o son privados? ¿Cómo se va a proteger la privacidad de los datos personales? No todo lo que está en Internet es público y mucho de lo que se sube a Internet está protegido por derechos de autor y hay toda una rama del derecho desarrollándose alrededor del uso de datos en salud.
KDnuggets es un portal líder en temas relacionados a ciencia de datos y aprendizaje automático que todos los años realiza una encuesta entre sus visitantes y suscriptores sobre cuáles son los programas más usados en ciencia de datos y aprendizaje automático. En 2019 recibieron cerca de 11.000 respuestas. En la Figura 3 se muestran los resultados comparativos de los años 2017, 2018 y 2019. Python encabeza la lista. Sin embargo, vale destacar que R, un software de acceso libre, es de los más usados por científicos de datos. Además, una herramienta de uso tan difundido como Excel no se queda atrás ya que es fácil de usar y continúa ampliando sus capacidades analíticas.
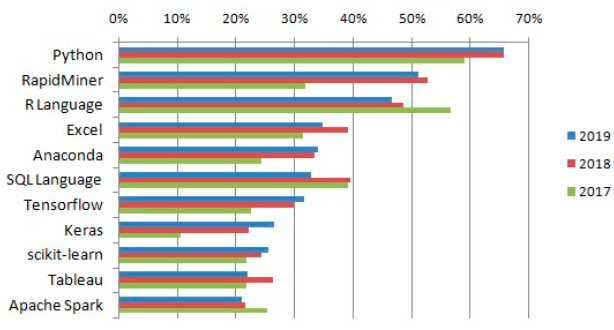
Figura 3. Herramientas más usadas en el análisis y ciencia de datos 2017-2019
KDnuggets - Analytics/Data Science 2019 Software Poll: top tools in 2019, and their share in the 2017, 2018 polls. Recuperado de: https://www.kdnuggets.com/2019/05/poll-top-data-science-machine-learning...
Las barras representan el porcentaje de personas que prefieren cada programa. El color verde corresponde a las respuestas obtenidas en el 2017; rojo, al año 2018 y azul, al año 2019.
Referencia bibliográfica
1- This is what happens in an Internet minute-2019, Lori Lewis y Chad Callahan. Recuperado de: https://lorilewismedia.com/

Marina Travacio, docente de la Cátedra de Química General e Inorgánica, Facultad de Farmacia y Bioquímica, UBA.









Dejar un comentario